.svg)
La toma de decisiones basada en datos es la clave detrás de todas las decisiones estratégicas de las empresas. Grandes volúmenes de datos fluyen desde diferentes fuentes de origen hasta el almacén de datos o cualquier herramienta de análisis para obtener información. Las empresas necesitan un espacio de trabajo rápido, fiable, escalable y fácil de usar para ingenieros de datos, analistas de datos y científicos de datos.
Hoy en día, a medida que aumentan la cantidad y la complejidad de la información, el problema de procesar y aprovechar los datos se hace más complejo de unificar. La capacidad de los equipos para crear prototipos y poner en funcionamiento soluciones basadas en datos también se ve obstaculizada por sistemas e instrumentos fragmentados, cada uno con capacidades restringidas, así como por la incapacidad de utilizar la ciencia de datos para crear opciones más inteligentes.
Los expertos en gestión de información suelen enfrentar dificultades para cerrar la brecha entre los datos en bruto y las alternativas que generan valor. Algunas de estas dificultades incluyen:
- Proporcionar un acceso sencillo y rápido a la información a gran escala.
- Implementación de aplicaciones de aprendizaje automático y streaming de calidad de producción.
- Utilizar más la ciencia de datos para apoyar la toma de decisiones.
Proporcionar un acceso sencillo y rápido a la información a gran escala.
Significa procesar datos estructurados y no estructurados, ingestando desde almacenamientos de datos no tradicionales y reduciendo el tiempo de procesamiento por lotes.
Implementación de aplicaciones de aprendizaje automático y streaming de calidad de producción.
Configurar, ajustar y escalar clústeres de Apache Spark para el equipo. Mantener los clústeres resistentes y actualizados con las últimas versiones. Programar, ejecutar y depurar aplicaciones en producción.
Utilizar más la ciencia de datos para apoyar la toma de decisiones.
Que apunta a la exploración y visualización interactiva de datos, la creación de cuadros de mando en tiempo real y la conexión con herramientas de Business Intelligence.
¿Qué es Azure Databricks?
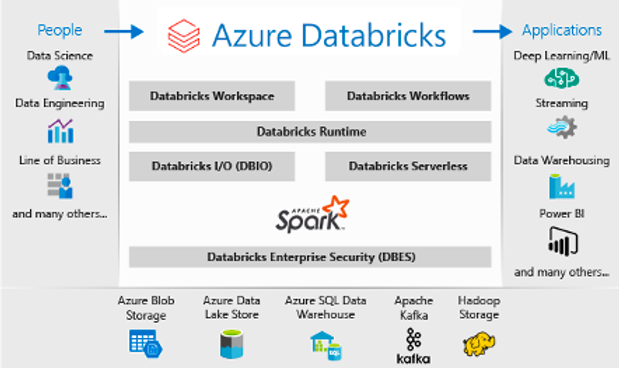
Teniendo en cuenta esto y algunos problemas adicionales en la unificación de la información a los que se enfrenta la ciencia de datos, es aquí donde Databricks entra en juego como solución. Databricks es una herramienta de ingeniería de datos basada en la nube que las empresas utilizan ampliamente para procesar y transformar grandes cantidades de datos y explorarlos. Permite a las organizaciones alcanzar rápidamente todo el potencial de la combinación de sus datos, procesos ETL (extraer, transformar y cargar) y Machine Learning.
Los procesos tradicionales de Big Data no solo son lentos a la hora de realizar las tareas, sino que también consumen más tiempo de configuración. Sin embargo, Databricks se basa en entornos distribuidos de computación en la nube como Azure, lo que facilita la ejecución de aplicaciones en CPU o GPU en función de las necesidades de análisis. Se dice que la plataforma Databricks es 100 veces más rápida que Apache Spark . Mejora la innovación, el desarrollo y también proporciona una mayor seguridad.
Databricks está integrada con Microsoft Azure, lo que la convierte en una plataforma analítica unificada (UAP), que acelera la innovación unificando la ciencia de datos, la ingeniería y el negocio.
Azure Databricks: Qué es y tres ventajas para elegirlo.
Estas son algunas de las principales razones por las que Azure Databricks es una gran opción para la ciencia de datos y las cargas de trabajo de big data.
Razón #1: Velocidad
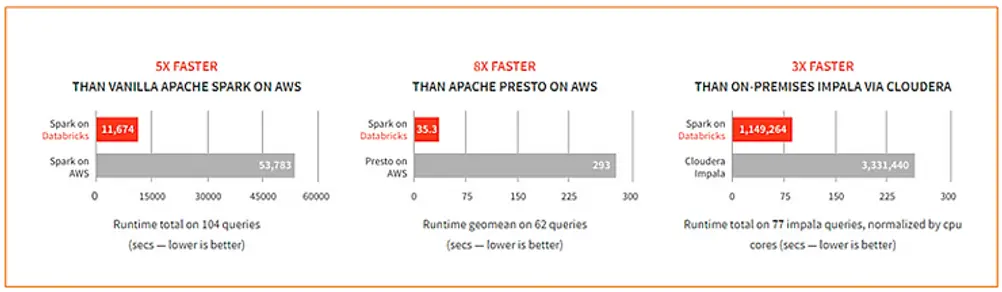
Cualquiera que esté familiarizado con Apache Spark sabe que es rápido. Puede funcionar hasta 100 veces más rápido que Hadoop MapReduce cuando se ejecuta en memoria, o hasta 10 veces más rápido cuando se ejecuta en disco. Azure Databricks es aún más rápido.
El equipo de Databricks proporciona una serie de mejoras de rendimiento además de Apache Spark normal. Entre ellas se incluyen el almacenamiento en caché, la indexación y las optimizaciones avanzadas de consultas. Los datos de evaluación comparativa que figuran a continuación, extraídos de un reciente artículo de Juliusz Sompolski y Reynold Xin en el blog de ingeniería de Databricks, muestran que estas optimizaciones contribuyen a un aumento del rendimiento de hasta 8 veces en comparación con otras plataformas SQL de big data similares. Si añadimos esto a las ganancias de rendimiento de 10 a 100 veces, podemos ver las evidentes eficiencias de procesamiento que proporciona este motor.
Razón #2: Seguridad
Azure Databricks se integra directamente con Azure Active Directory (AAD) de forma inmediata, sin necesidad de configuración personalizada. Esto difiere significativamente de Apache Spark en Azure HDInsight, donde la integración de AAD es una característica premium que requiere una configuración considerable con Apache Ranger.
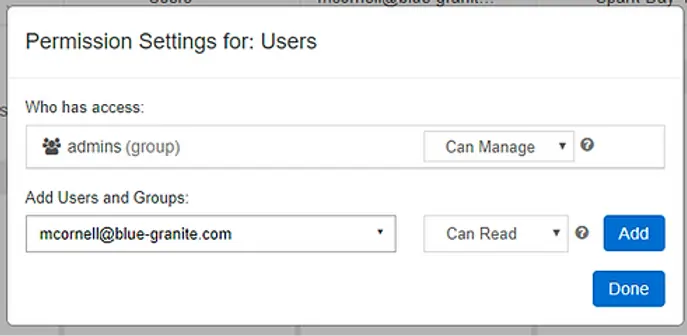
Después de crear el servicio Azure Databricks e inicializar el espacio de trabajo Databricks, los usuarios con acceso pueden simplemente ir a la URL del espacio de trabajo e iniciar sesión utilizando sus credenciales de AAD.
Una vez dentro del espacio de trabajo de Databricks, los usuarios administrativos pueden navegar a la consola de gestión, lo que les permite añadir, eliminar y gestionar fácilmente usuarios dentro del espacio de trabajo. Incluso pueden invitar a usuarios externos (aquellos que no pertenecen al mismo AAD) al espacio de trabajo, siempre que el usuario pertenezca a otro AAD.

Razón #3: Colaboración
La colaboración es la tercera razón para elegir Azure Databricks para cargas de trabajo de ciencia e ingeniería de datos. Azure Databricks proporciona una plataforma en la que los científicos e ingenieros de datos pueden compartir fácilmente espacios de trabajo, clústeres y tareas a través de una única interfaz. También pueden enviar su código y artefactos a herramientas populares de control de código fuente como GitHub.
Dentro de Azure Databricks, los usuarios pueden iniciar clústeres, crear cuadernos interactivos y programar trabajos para ejecutar notas. Utilizando el portal de Azure Databricks, los usuarios pueden compartir fácilmente estos artefactos con otros. Esto permite a los usuarios crear y construir modelos en colaboración en el mismo cuaderno en tiempo real, reutilizar activos de datos, bibliotecas y recursos informáticos en el mismo clúster, o reutilizar y supervisar trabajos programados.
Los ingenieros y científicos de datos que utilizan herramientas populares de control de código fuente como GitHub y Bitbucket para gestionar su código pueden seguir haciéndolo con Azure Databricks. Esto permite a las empresas que han adoptado procesos de control de código fuente independientes en toda la empresa seguir utilizando sus métodos establecidos. Azure Databricks facilita la vinculación y sincronización de artefactos como Notas a un repositorio Git donde pueden existir, incluso si el espacio de trabajo de Azure Databricks desaparece.
Azure Databricks, el nuevo e interesante servicio de Azure, ayuda a las empresas a innovar de forma más eficaz y eficiente junto a Big Data. Si estás interesado en saber más sobre este servicio y cómo podría encajar en la plataforma de datos de tu empresa, ponte en contacto con nosotros o explora las ventajas de datos en 2022 que podemos ofrecerte.
Si desea obtener más información sobre cómo podemos ayudarle a implantar soluciones para mejorar sus procesos y obtener mejores resultados para su empresa, póngase en contacto con nosotros.