
As of this writing, Tesla is the most valuable automaker in the world by market cap, besting other worldwide juggernauts such as Toyota, Volkswagen, and even Detroit’s “Big Three”. https://www.statista.com/chart/22043/market-capitalization-of-publicly-traded-car-manufacturers/
But How?
Audi’s CEO has stated, in an interview with German newspaper Handelsblatt, that Tesla is two years ahead of the industry in both in-car software and autonomous capabilities. But we are willing to argue that they are even further ahead of the rest of the automotive industry with respect to data assets and expertise, which is arguably the most important pillar of Tesla’s operations. We cannot make a cogent argument for Tesla’s valuation, but we can share perspective on their impressive use of data and some advantages it gives them.
Test and Learn
Test and learn is part of the standard practice for builders of software, cars or just about anything else. In the automotive industry, however, this learning and deployment cycle has (at least historically), largely stopped the moment the wheels hit the pavement. While, yes, there have been safety recalls and some aftermarket control units you could use to increase performance and efficiency, vehicle manufacturers generally opted for very limited upgrades after the car left the dealership’s lot.
Tesla Inc., however, fundamentally designed their manufacturing and software development effort to be data driven and iterative, especially after the car has left the factory. “Over the air” updates and improvements to the Tesla software have been part of the strategy since the beginning. In fact, the argument exists that Tesla’s key advantage is their data gathering, testing, learning and improvements AFTER being in the hands of the owner.
What is the Tesla Data Engine?
Tesla now has over 500,000 cars on the road. While this is a fraction of larger car makers, Tesla is using every car on the road to gather and analyze a river of data. Every recent Tesla has 8 cameras, 12 ultrasonic sensors and one forward-facing radar. These tools and other sensors in the car are constantly recording video and data such as speed, acceleration, braking and battery information for every mile those cars are driving. TeslaCam in Sentry mode is even gathering video when a Tesla is parked. Much of this data is available to Tesla as part of their terms of use and can be gathered remotely via the car’s connection to the internet.
Tesla then uses machine learning neural networks to help understand vehicle performance and beta test for improvements. For example, if you own a Tesla and rarely drive it in Autopilot mode, your vehicle is still constantly pretending like it is in Autopilot and noticing the discrepancies in your driving and the neural network’s driving. Tesla is then able to transmit inaccuracies within their neural network to its research team, and use the data to retrain its neural network, deploy beta versions of the new test, collect feedback, iterate, and improve.
As an example, consider the case of a stop sign obscured by foliage. Tesla will note drivers stopping at this intersection, create a trigger noting that Tesla auto-pilot may have missed that there is a stop sign, and convey the images seen back to the data science team. Tesla now has an excellent set of images to train it’s AI on how to detect stop signs obscured by foliage. With more cars on the road, generating data and images and unique situations, Tesla learns and improves quickly. Tesla has now passed 2 BILLION miles driven on autopilot. Waymo or other car makers cannot match actual miles driven from the 500,000+ Tesla’s generating new real time data every day.
Just having data is one thing, but using it well is another – Elon Musk has said “It’s actually quite a challenge to process that data, and then train against that data, and have the vehicle learn effectively from the data, because it’s just a vast quantity.”
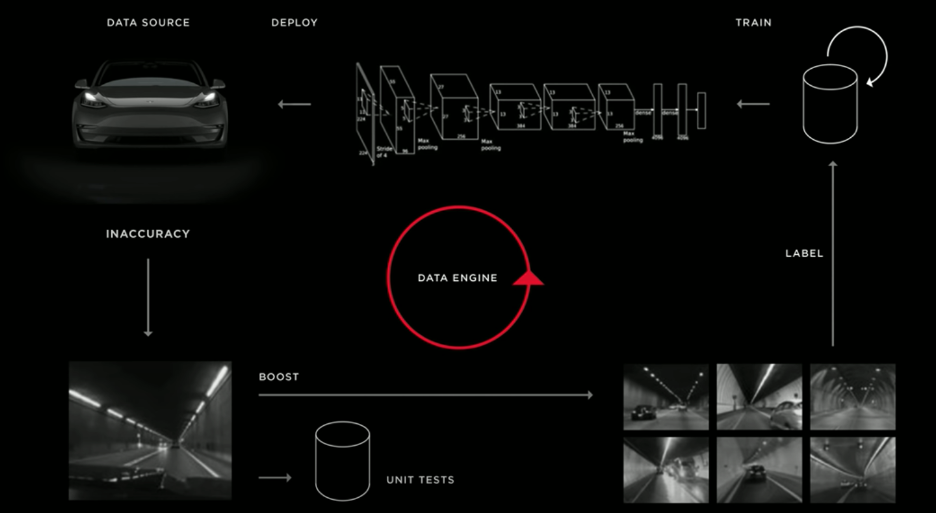
Source: Tesla Autonomy Day 2019
Tesla has built a global infrastructure and team to ensure it maximizes its learning from Tesla’s vast river of data. They call it the Tesla “Data Engine”. The data engine is shown above and is a classic “flywheel” effect – where more data allows for faster training and improvement, which then sells more cars because of the advantages/improvements generated, which then leads to even more data and faster iterations because Tesla has more cars on the road gathering data.
To reiterate – Tesla’s Andrej Karpathy, Senior Director of AI, explains some of the main features of their Data Engine during his speech during Tesla’s Autonomy Day 2019:
“We have a ML mechanism by which we can ask the fleet to source us examples that look like [example X], and the fleet might respond with images that contain those patterns… We would go in, and we would annotate those [examples] and the performance of the fleet identifying [that example]. We look for lots of things, all the time – we look for rare cases. If we can source these at scale, we can annotate these correctly, and the neural network will learn how to deal with them in the real world. If we detect that the neural network might be uncertain, or we detect that the driver intervenes, we can create this trigger infrastructure that sends us data on those inaccuracies.”
Tesla’s Data Engine is a unique advantage
Tesla’s Data Engine idea is relatively simple in concept but difficult to replicate. Tesla’s pipeline of data is large, continuous, structured, and real- which are all essential when training a neural network.
Tesla’s data advantage comes from the entire fleet: the global network of drivers constantly testing Tesla’s programming themselves and the impressive data scientists utilizing compute power in Palo Alto to retrain Tesla’s Autopilot and Self-Driving neural networks. Ultimately, the more cars on the road, the better their entire fleet will be at driving safely and protecting its users, and the closer they will be to having a full self-driving vehicle.
In our eyes, Tesla is not simply an automotive company – they are an AI/ML company that deploys cars around the world to gather data. Ultimately, that data, Tesla’s data science expertise, and the potential insights generated (perhaps even beyond the automotive industry) may be a part of explaining their extraordinary valuation.
.png?width=360&height=240&name=email%20sign%20up%20graphic(2).png)