

Si tiene una plataforma SaaS que cuenta con un número considerable de usuarios, es posible que ya se haya planteado esta pregunta varias veces.
%252525252018.21.34.png)
En el ciclo de vida del producto, llega un momento en el que la forma en que se han construido las cosas empieza a afectar al rendimiento de los nuevos escenarios de casos de uso.
El producto se ha diseñado y concebido para cumplir una serie de requisitos, pero éstos cambian más adelante y el sistema se adapta para satisfacerlos. Este bucle de iteración se repite una y otra vez una vez que el producto ha superado la fase de MVP y alcanza un cierto nivel de madurez con una base de usuarios considerable.
Las decisiones arquitectónicas que se habían tomado al concebir el producto, junto con las prácticas de desarrollo establecidas, comprometen la forma de implementar futuras características. A medida que el producto empieza a crecer a lo largo de las iteraciones, se implementan nuevas características siguiendo la arquitectura y las prácticas existentes, pero éstas podrían no ajustarse bien a las características implementadas. Entonces, los usuarios adoptan estas características y la base de usuarios crece.
Un caso típico de esto es haber optado por utilizar una base de datos no relacional porque se tenían muchos datos no estructurados que modelar, para luego descubrir que el sistema acaba requiriendo complejas consultas y uniones entre colecciones.
A medida que crece el tráfico, el sistema puede sufrir una "muerte por mil cortes" de rendimiento. Esto significa que el rendimiento del sistema disminuye, pero no hay una causa específica (sino varias) que explique por qué. En un entorno sin servidor acabas pagando un montón de dinero , pero la caída de rendimiento se resuelve escalando el sistema. Por otro lado, en un entorno de servidor único tus usuarios sufren la caída de rendimiento de tu sistema, lo que normalmente se traduce en navegación lenta por las páginas, carga infinita de spinners , etc.
Observabilidad
La observabilidad se refiere a la capacidad de supervisar y comprender el estado interno de un sistema mediante el examen de sus métricas. Va más allá de la supervisión tradicional al centrarse no sólo en la salida del sistema, sino también en su rendimiento y comportamiento a lo largo del tiempo. Esto es clave para diagnosticar y resolver problemas de rendimiento.
La capacidad de observación de los sistemas permite mejorar la supervisión y la resolución de problemas .
Se puede implementar en toda la pila tecnológica, lo que significa que se puede medir cualquier componente de la plataforma, desde los servicios de back-end hasta las aplicaciones de front-end, incluidas métricas muy específicas como los tiempos de consulta y solicitud para los servicios de back-end o el tiempo hasta el primer byte para las aplicaciones de front-end. Algunas de estas herramientas son Datadog o New Relic, ambas de pago, o Grafana + Prometheus si quieres una alternativa Open Source. Complementadas con Google Analytics, para entender el comportamiento de los usuarios, son herramientas realmente potentes.
Cómo el uso de Datadog ahorró a nuestro cliente miles de dólares en servicios en la nube
En el mundo real, uno de los clientes para los que hemos creado un sistema de pago para máquinas expendedoras está alcanzando un pico de uso tras conseguir que una gran cadena de supermercados de Sudamérica utilice el sistema de pago como parte del programa de beneficios para sus empleados.
En muy poco tiempo, añadieron más de 2.000 usuarios al sistema de lunes a sábado. Uno de los primeros síntomas de que el sistema no estaba gestionando correctamente esta carga fue que los usuarios se quejaban de la lentitud de los pagos a la hora de comer, la hora punta.
Hicimos algunas pruebas con pequeños retoques en el código para ver si podíamos encontrar la razón de por qué el sistema iba tan lento, pero las mejoras fueron realmente pequeñas. Ninguna de nuestras teorías era cierta.

En nuestra oficina de Denver tenemos un cartel de neón que resume por qué es necesaria la observabilidad. Teníamos nuestras opiniones sobre lo que estaba pasando, pero no teníamos datos que las respaldaran.
La solución inmediata fue simplemente conseguir un VPS más grande para manejar la nueva carga, pero la factura de AWS se disparó a 3 veces la cantidad anterior, por lo que con el fin de entender lo que estaba pasando instalamos Datadog en toda la pila. Queríamos monitorizar trazas, métricas de host (CPU, memoria, IO), métricas de servidor web (latencia, consultas/seg) y métricas de base de datos (consultas/seg, latencia de consultas, concurrencia).
Lo primero que descubrimos fue un trabajo programado que hacía estallar el rendimiento cada 30 minutos, eliminarlo resolvió muchos de los problemas.
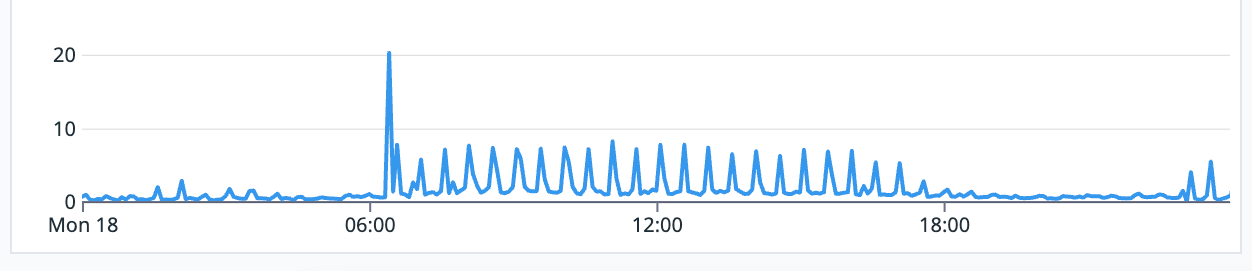
[Datadog] latencia en segundos, los picos son generados por un proceso que bloquea la base de datos cada 30 minutos.
Posteriormente, se realizó una investigación más detallada para encontrar las principales consultas que presentaban mayor latencia durante la hora punta. Para mejorar el rendimiento de esas consultas, tanto en la base de datos como en el código del servidor, buscamos y encontramos cuellos de botella, sobre todo en la base de datos.
%252525252019.10.29.png)
[Datadog] Consultas más acertadas
Tras unos cuantos despliegues en producción, podíamos volver al antiguo hardware de servidor para gestionar la nueva carga de tráfico y reducir el pago hasta la línea de base.
Hoy, como parte de nuestro trabajo de mantenimiento continuo de este sistema, estamos vigilando las métricas del servidor, utilizando las alertas y monitores de Datadog, para que nos avisen cuando la latencia se salga de los límites, de modo que podamos rastrear qué cambio de código lo causó, o si hay un crecimiento en el tráfico.
Lo que Nimble Gravity puede hacer por usted
En Nimble Gravity nos encantan las métricas y hemos ayudado a decenas de clientes a tomar decisiones basadas en datos. Además de crear productos y ayudar a los clientes a transformar su visión en un MVP y lanzarlo al mercado, queremos unirnos al viaje del cliente durante el ciclo de vida del producto.
Ofrecemos servicios de estrategia técnica, desarrollo de software y productos, y servicios de mantenimiento continuo, que incluyen la configuración de herramientas de observabilidad como Datadog y la investigación sobre cómo resolver problemas de rendimiento en sitios web y aplicaciones móviles.
Si cree que podemos ayudarle, no dude en ponerse en contacto con nosotros aquí.